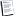 Oxidisation of Seagate & WDC PCBs
Oxidisation of Seagate & WDC PCBs
Sergey Kubushyn wrote:
In sci.electronics.repair Arno wrote:
In comp.sys.ibm.pc.hardware.storage Sergey Kubushyn
wrote:
In sci.electronics.repair Arno wrote:
In comp.sys.ibm.pc.hardware.storage Sergey Kubushyn
wrote:
In sci.electronics.repair Franc Zabkar
wrote:
On Thu, 8 Apr 2010 14:03:39 -0700 (PDT), whit3rd
put finger to keyboard and composed:
On Apr 8, 12:11?am, Franc Zabkar
wrote:
Is this the fallout from RoHS?
Maybe not. There are other known culprits, like the drywall
(gypsum board,
sheetrock... whatever it's called in your region) that outgasses
hydrogen
sulphide. Some US construction of a few years ago is so bad
with this
toxic and corrosive gas emission that demolition of nearly-new
construction
is called for.
Corrosion of nearby copper is one of the symptoms of the nasty
product.
It's not just Russia that has this problem. The same issue comes
up frequently at the HDD Guru forums.
I'm right here in the US and I had 3 of 3 WD 1TB drives failed at
the same time in RAID1 thus making the entire array dead. It is
not that you can simply buff that dark stuff off and you're good
to go. Drive itself tries to recover from failures by rewriting
service info (remapping etc.) but connection is unreliable and it
trashes the entire disk beyound repair. Then you have that
infamous "click of death"... BTW, it is not just WD; others are
also that bad.
It is extremly unlikely for a slow chemical process to achive this
level of syncronicity. About as unlikely that it would be fair to
call it impossible
Your array died from a different cause that would affect all drives
simultaneously, such as a power spike.
Yes, they did not die from contacts oxidation at that very same
moment. I can not even tell they all died the same month--that
array might've been running in degraded mode with one drive dead,
then after some time second drive died but it was still running on
one remaining drive. And only when the last one crossed the Styx
the entire array went dead.
Ah, I see. I did misunderstand that. May still be something
else but the contacts are a possible explanation with that.
I don't think it is something else but everything is possible...
I don't use Windows so my machines are never turned off unless there
is a real need for this. And they are rarely updated once they are
up and running so there is no reboots. Typical uptime is more than a
year.
So your disks worked and then refused to restart? Or you are running
a RAID1 without monitoring?
They failed during weekly full backup. One of the files read failed
and they entered that infinite loop of restarting themself and
retrying. Root filesystem was also on that RAID1 array so there was
no other choice than to reboot. And on that reboot all 3 drives
failed to start with the same "click of death" syndrome.
I don't know though how I could miss a degradation alert if there
was any.
Well, if it is Linux with mdadm, it only sends one email per
degradation event in the default settings.
Yep, I probably missed it when shoveling through mountains of spam.
All 3 drives in the array simply failed to start after reboot.
There were some media errors reported before reboot but all drives
somehow worked. Then the system got rebooted and all 3 drives
failed with the same "click of death."
The mechanism here is not that oxidation itself killed the drives.
It never happens that way. It was a main cause of a failure, but
drives actually performed suicide like body immune system kills
that body when overreacting to some kind of hemorrargic fever or so.
The probable sequence is something like this:
- Drives run for a long time with majority of the files never
accessed so it doesn't matter if that part of the disk
where they are stored is bad or not
I run long smart selftest on all my drives (RAID or no) every
14 days to prevent that. Works well.
- When the system is rebooted RAID array assembly is
performed
- While this assembly is being performed a number of sectors
on a drive found to be defective and drive tries to remap
them
- Such action involves rewriting service information
- Read/write operations are unreliable because of failing
head contacts so the service areas become filled with
garbage
- Once the vital service information is damaged the drive is
essentially dead because its controller can not read vital
data to even start the disk
- The only hope for the controller to recover is to repeat
the read in hope that it might somehow get read. This is
that infamous "click of death" sound when drive tries to
read the info again and again. There is no way it can
recover because that data are trashed.
- Drives do NOT fail while they run, the failure happens on
the next reboot. The damage that would kill the drives on
that reboot happened way before that reboot though.
That suicide also can happen when some old file that was not
accessed for ages is read. That attempt triggers the suicide chain.
Yes, that makes sense. However you should do surface scans on
RAIDed disks regularly, e.g. by long SMART selftests. This will
catch weak sectors early and other degradation as well.
I know but I simply didn't think all 3 drives can fail... I thought I
have enough redundancy because I put not 2 but 3 drives in that
RAID1... And I did have something like a test with regular weekly
full backup that reads all the files (not the entire disk media but
at least all the files on it) and that was that backup that triggered
disk suicide.
Anyway lesson learned and I'm taking additional measures now. It was
not a very good experience loosing some of my work...
BTW, I took a look at brand new WDC WD5000YS-01MPB1 drives, right out
of the sealed bags with silica gel and all 4 of those had their
contacts already oxidized with a lot of black stuff. That makes me
very suspicious that conspiracy theory might be not all that
crazy--that oxidation seems to be pre-applied by the manufacturer.
MUCH more likely that someone ****ed up in the factory.
|